Some Known Questions About Data Science Course Uk.
Table of ContentsEverything about Data Scientist Course London

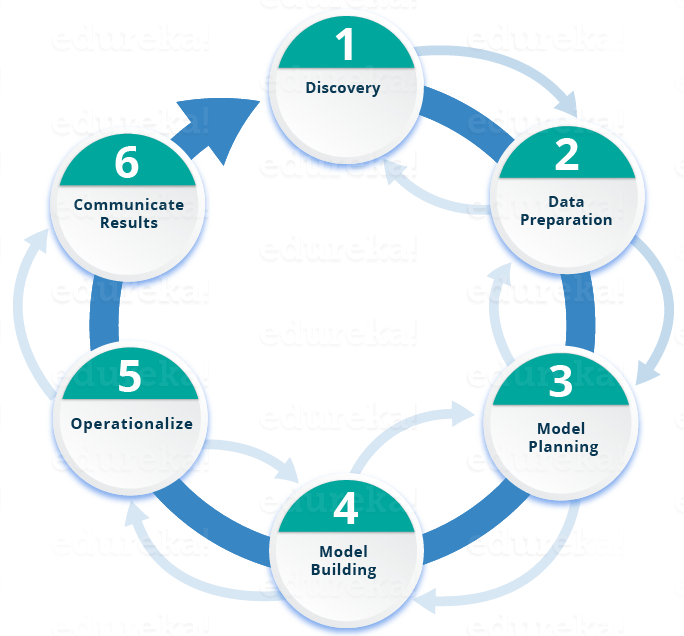
For that reason, it is very important for you to adhere to all the stages throughout the lifecycle of Information Science to ensure the smooth performance of the job. Here is a brief introduction of the major stages of the Data Scientific Research Lifecycle: Before you start the job, it is necessary to understand the numerous specs, requirements, concerns and called for spending plan. You should have the capability to ask the right concerns. Here, you analyze if you have the called for sources present in regards to people, technology, time and also data to sustain the project. In this stage, you likewise require to mount business problem and also formulate first hypotheses (IH )to evaluate. You require to check out, preprocess and also condition information before modeling. Even more, you will execute ETLT (essence, change, load as well as change )to get data into the sandbox. Allow's look at the Analytical Evaluation flow below. You can use R for information cleansing, change, as well as visualization. This will aid you to spot the outliers and also establish a partnership in between the variables. Once you have cleansed and also prepared the information, it's time to do exploratory analytics on it. Allow's see how you can accomplish that. Right here, you will certainly determine the techniques and also techniques to draw the connections between variables. These partnerships will certainly establish the base for the algorithms which you will carry out in the following stage. Allow's have an appearance at various version planning tools. R has a total set of modeling abilities as well as gives an excellent environment for building interpretive designs. SQL Analysis services can carry out in-database analytics utilizing typical information mining functions as well as fundamental predictive designs - data science course. SAS/ACCESS can be utilized to accessibility information from Hadoop as well as is utilized for creating repeatable and reusable version flow diagrams. Although, lots of tools exist on the market however R is the most typically used tool. Since you have actually got insights into the nature of your information and have determined the algorithms to be utilized. In the following stage, you will apply the formula as well as build up a model. Here you require to take into consideration whether your existing devices will suffice for running the versions or it will need a more durable atmosphere (like fast and also parallel processing). You will certainly evaluate different learning strategies like category, association and also clustering to develop the version. You can accomplish version building via the adhering to tools. In this stage, you provide final records, briefings, code and also technical records. In enhancement, often a pilot job is additionally carried out in a real-time production atmosphere. This will certainly offer you a clear photo of the efficiency as well as various other related restraints on a small range prior to click now full implementation. Currently it is essential to review if you have actually been able to accomplish your objective that you had intended in the first stage. Currently, I will take an instance study to describe you the you can check here various phases defined above. Suppose we can predict the incident of diabetes as well as take proper measures ahead of time to stop it?In this use situation, we will certainly predict the occurrence of diabetes mellitus taking advantage of the entire lifecycle that we went over earlier. Allow's undergo the various actions. Initially, we will certainly collect the data based on the medical background of the patient as gone over in Stage 1. You can describe the example information listed below. As you can see, we have the numerous features as discussed below. npreg Number of times expecting sugar Plasma sugar focus bp Blood stress skin Triceps skinfold thickness bmi Body mass index ped Diabetic issues pedigree feature age Age revenue Revenue, Currently, once we have the information, we require to tidy and prepare the data for data analysis. Here, we have arranged the data into a single table under different characteristics making it look much more organized. data science bootcamp uk. Let's look at the sample information listed below. This data has a great deal of inconsistencies. In the column npreg, "one" is written in words, whereas it ought to be in the numeric kind like 1. In column bp among the values is 6600 which is difficult (at the very least for human beings) as bp can not data scientist course london increase to such significant worth. As you can see the Revenue column is blank as well as likewise makes no sense in predicting diabetes. Consequently, it is repetitive to have it here and also ought to be removed from the table. Allow's see how?Since, we currently have the major features for evaluation like npreg, bmi, and so on, so we will make use of supervised learning method to build a version right here. Even more, we have particularly utilized decision tree since it takes all characteristics right into consideration in one go, like the ones which have a linear partnership as well as those which have a non-linear partnership. In our case, we have a straight relationship in between npreg and age, whereas the nonlinear partnership between npreg and also ped. Decision tree designs are also extremely durable as we can utilize the various combination of credit to make numerous trees as well as after that ultimately carry out the one with the optimum effectiveness.